Learning to Play Atari in a World of Tokens
Abstract
Model-based reinforcement learning agents utilizing transformers have shown improved sample efficiency due to their ability to model extended context, resulting in more accurate world models. However, for complex reasoning and planning tasks, these methods primarily rely on continuous representations. This complicates modeling of discrete properties of the real world such as disjoint object classes between which interpolation is not plausible. In this work, we introduce discrete abstract representations for transformer-based learning (DART), a sample-efficient method utilizing discrete representations for modeling both the world and learning behavior. We incorporate a transformer-decoder for auto-regressive world modeling and a transformer-encoder for learning behavior by attending to task-relevant cues in the discrete representation of the world model. For handling partial observability, we aggregate information from past time steps as memory tokens. DART outperforms previous state-of-the-art methods that do not use look-ahead search on the Atari 100k sample efficiency benchmark with a median human-normalized score of 0.790 and beats humans in 9 out of 26 games.
Architecture
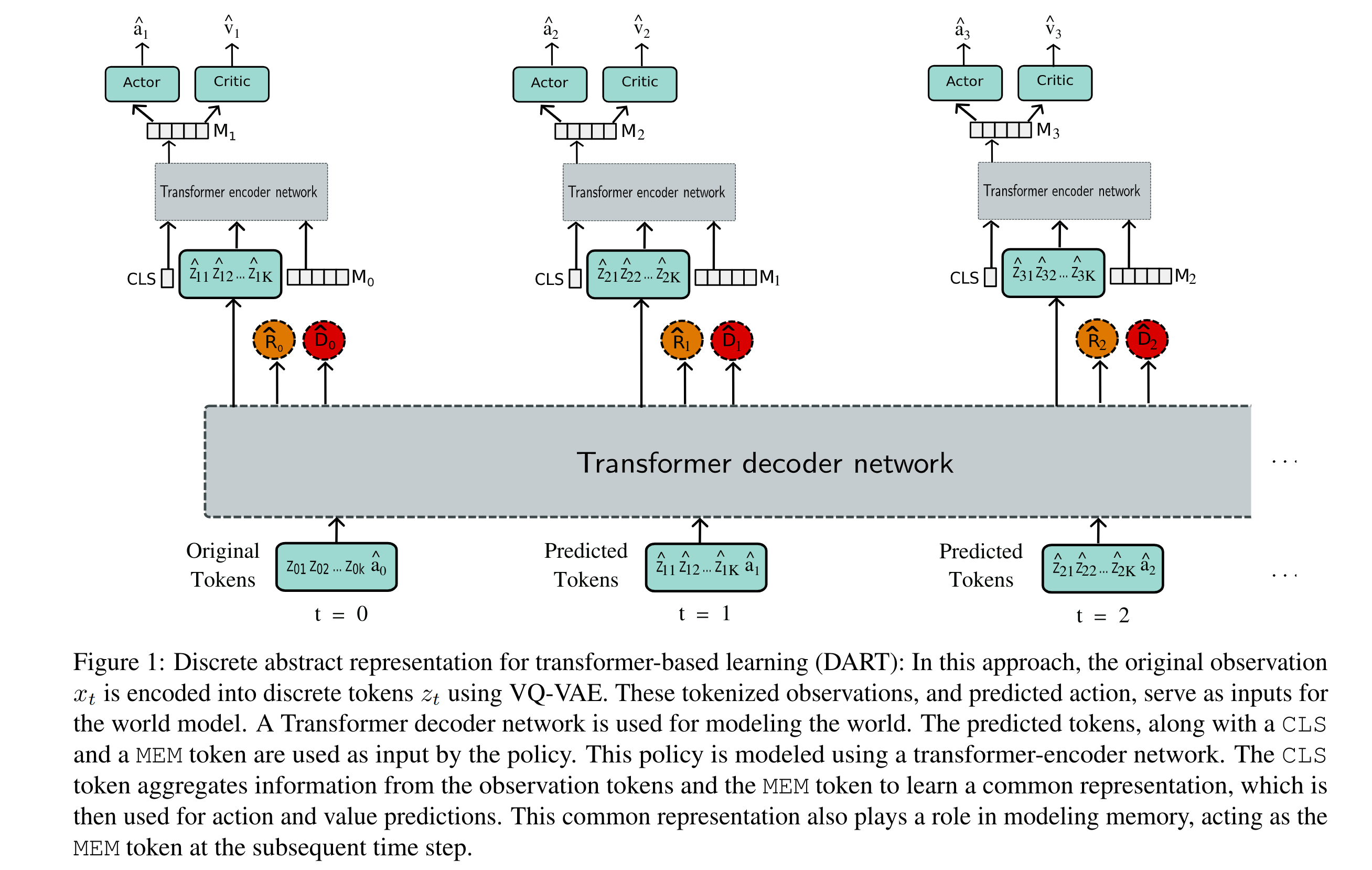
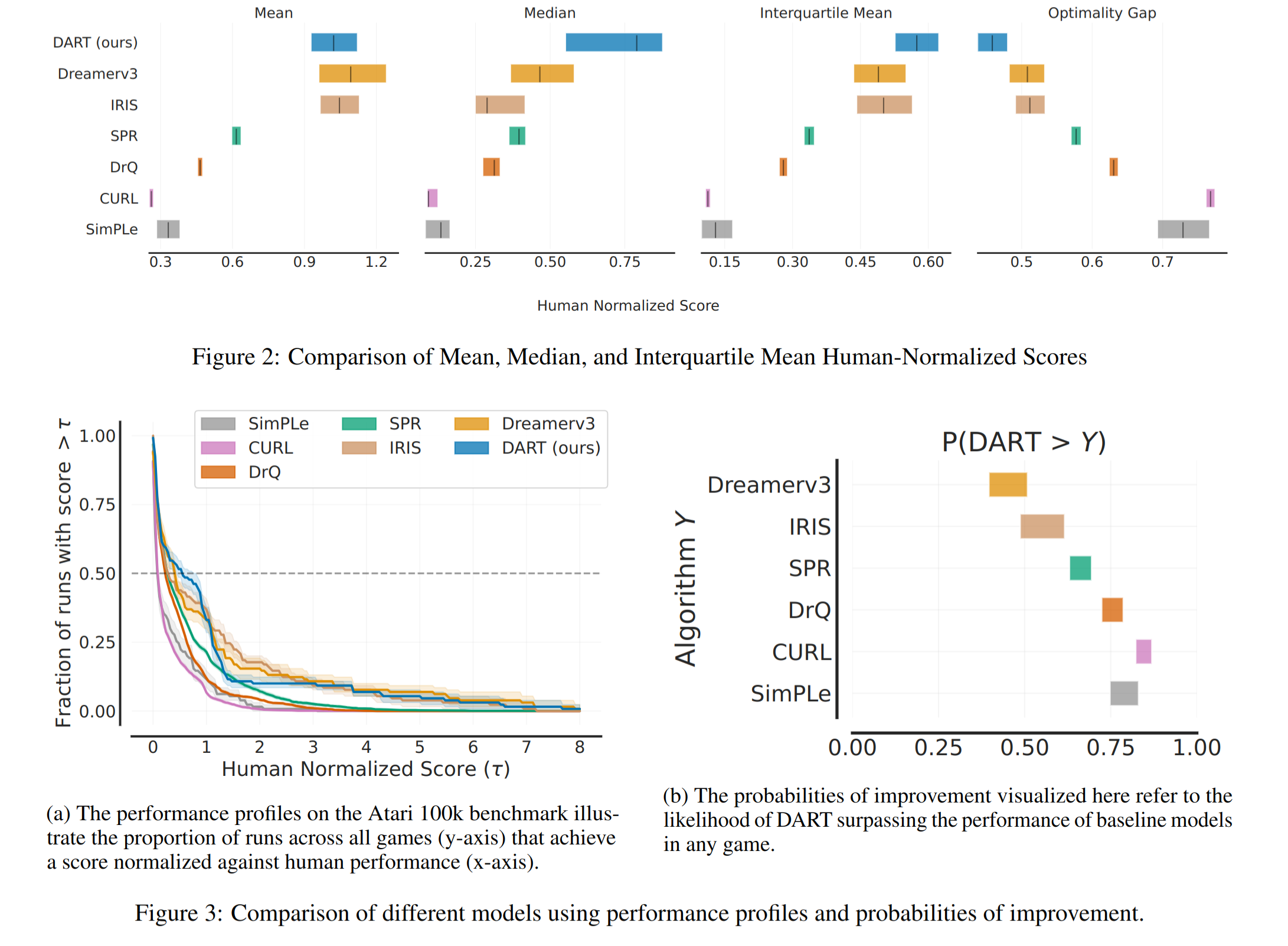
Results
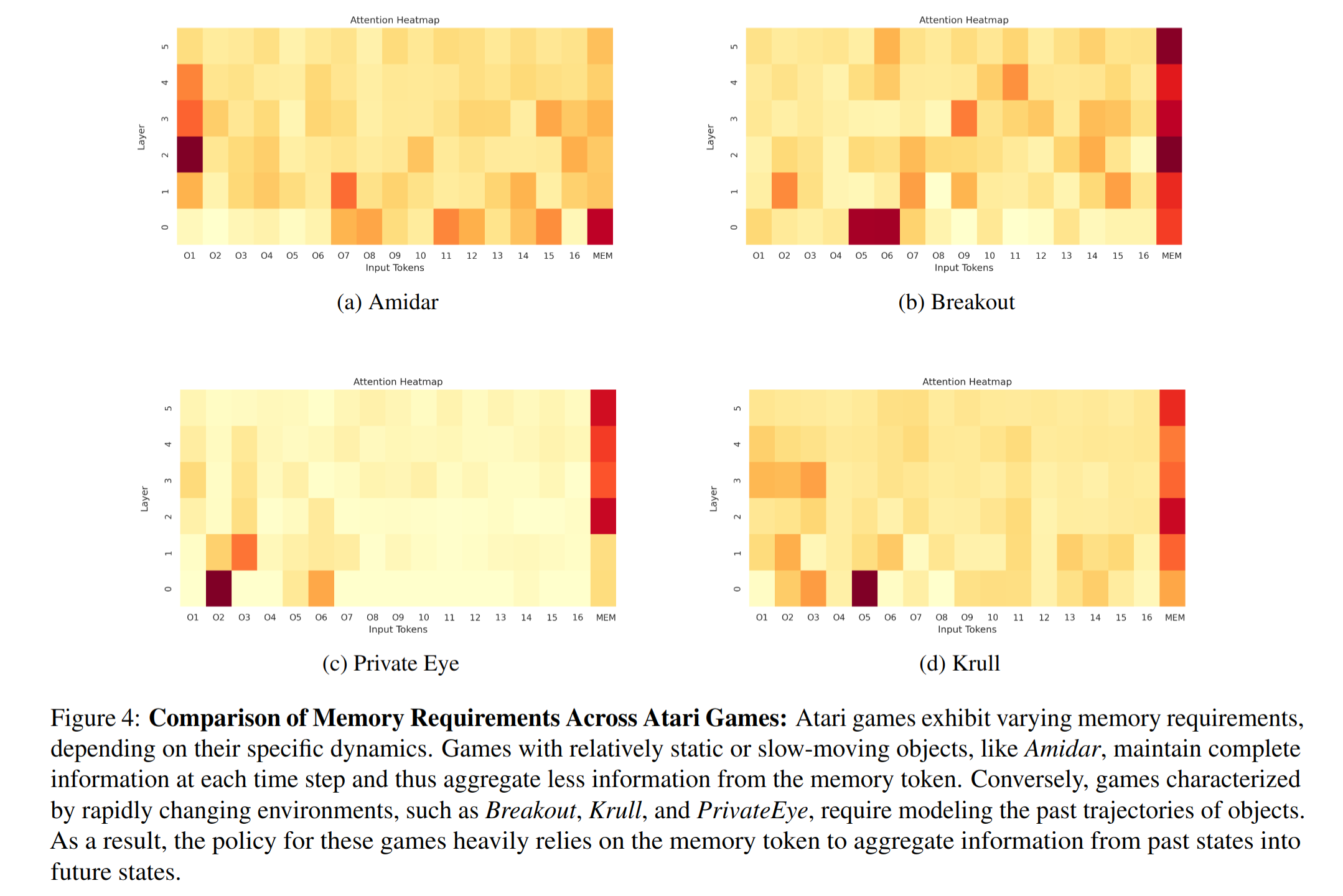
Interpretability
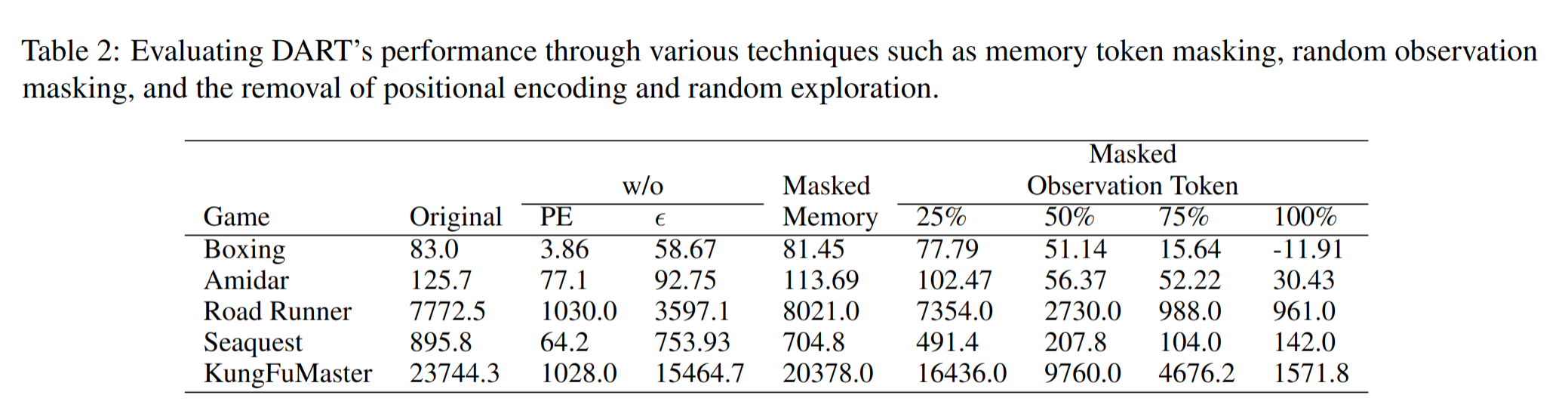
Ablation
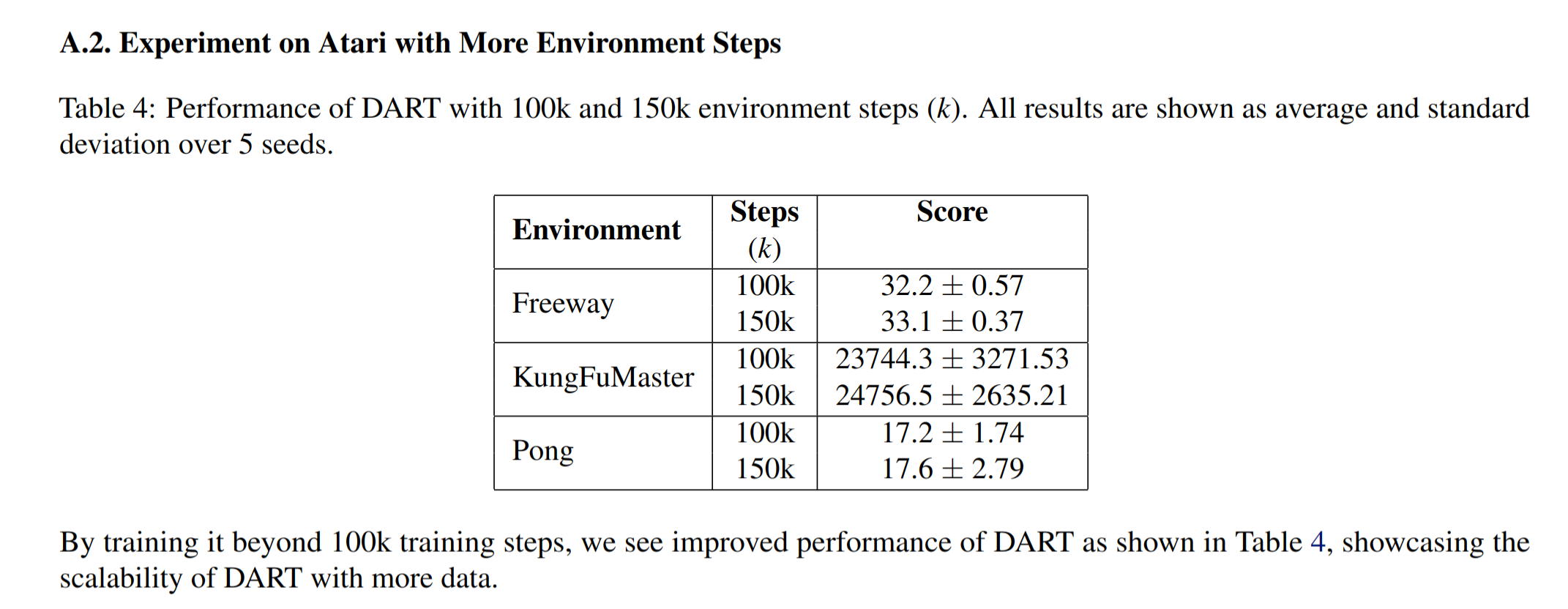
Scalability
Conclusion
In this work, we introduced DART, a model-based reinforcement learning agent that learns both the model and the policy using discrete tokens. Through our experiments, we demonstrated our approach helps in improving performance and achieves a new state-of-the-art score on the Atari 100k benchmarks for methods with no look-ahead search during inference. Moreover, our approach for memory modeling and the use of a transformer for policy modeling provide additional benefits in terms of interpretability. As of now, our method is primarily designed for environments with discrete action spaces. This limitation poses a significant challenge, considering that many real- world robotic control tasks necessitate continuous action spaces. For future work, it would be interesting to adapt our approach to continuous action spaces and modeling better-disentangled tokens for faster learning.
BibTeX
@article{agarwal2024learning,
title={Learning to Play Atari in a World of Tokens},
author={Agarwal, Pranav and Andrews, Sheldon and Kahou, Samira Ebrahimi},
booktitle={International Conference on Machine Learning (ICML)},
year={2024}
}